2. CRITICAL SURVEY OF LITERATURE
This chapter gives an overview of the Big Data clustering techniques and the distance and the similarity measures used by them. Clustering using power method and its convergence techniques are described. The need of Hadoop to handle Big Data is been explained.
2.1 MACHINE LEARNING
Machine learning is the method of analyzing data that uses algorithm that learns continuously from the data without being programmed explicitly. They learn themselves when they are exposed to new data. Machine learning is similar to that of data mining to search for the patterns in the data [20]. Machine learning uses these data to detect patterns and adjust program actions accordingly. Facebook, web search engine, smart phones, page ranking etc. uses machine learning algorithms for its processing. It constructs program with the characteristics that automatically adjusts itself to increase the performance using the existing data. The motivation of machine learning is to learn automatically and identify the patterns to take decisions based on them. Machine learning is divided three methods namely [42],
- Supervised learning or Predictive learning
- Unsupervised learning or Descriptive learning
- Semi supervised learning.
2.1.1 Supervised Learning
Supervised learning also called as the predictive learning is a method of mapping the inputs and the outputs, given a set of training set
∑j=1Paijand
ajtotal number ofspecies j
∑i=1Paij. Then, the Chi-square distance is given as
Xih2=∑j=1p1aijahjah-aijai2
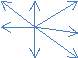
Chebyshev Distance (Maximum valuedistance) – It is the defined as the vector space where the distance between any two vectors is greatest of the distance along any coordinate dimension. It is call as max metric or L metric [50,52].
|
|
1 | 1 |
|
|
1 | 1 |
| 1 | 1 | 1 |
 1
1 1
1It is the maximum distance between the points in a single dimension. The formula computes the distance between two points
X=x1x2∙∙∙∙∙xnand
Y=y1y2∙∙∙∙∙ynis
Dchebp,q=maxi=xj-yj
Where
xiand
yjare the values of the
jthvariable at points X and Y. This is equal to the limit
limk→∞∑1n(pi-qik)1k
Bit Vector Distance – Let there be a N*N matrix then the bit vector distance is found at each point having d dimensions using Mb(Pi,Pj) as a d bit vector. If the xth dimension of point is greater than the numerical value the bit X of Mb (Pj,Pi) is set to 0.
Mahalanobis distance – The Mahalanobis distance is given based on the correlation structure of the data points and the individual points [53,54]. The Mahalanobis distance is computed as
Mi=(yi-y̅)S-1(yi-y̅)
where
yi= data of the ith row
Y – Row of the means
S – the estimated covariance matrix
Let X be an N*p matrix. Then the ith row of X is
xiT=(xi1……xip). The Mahalanobis distance is given as
dMH(i,j)=(xi-xj)T Σ-1xi-xj
Here Σ is the
p×psample covariance matrix. To perform it on quadratic multiplication, the mean difference is obtained and multiplied by the covariance after obtaining its transpose.
T2 Distance Measure – It is the square of Mahalanobis distance. So
Ti2=Mj2. The T2 Distance measure is given by the formula[52,54]
UCLT2=(n-1)2n1-β:p2:n-p-12
Where n is the number of observations and p is the number of variables.
2.4 SIMILARITY MEASURES
It is a metric used to measure the similarity between two objects. It compares the similarity and diversity of sample sets. It is defined as the size of the intersection divided by the size of sample sets. Given two sequence of measurements
X=x1,x2,∙∙∙∙∙,xnand
Y=y1,y2,∙∙∙∙∙,yn, the dependencies between X and Y give the similarity between them. The similarity measure can be defined as the function that becomes the degree between a pair of text objects. The value of similarity lies between 0 and 1. If the value is close to 0 then, the instance or data objects are said to be similar and if it is one they are dissimilar. A metric is said to be similar if it satisfies the following properties [55,56].
- Limited range – The value of the data points is less than the largest similarity measure
S(X,Y)≤S0
- Reflexivity
SX,Y=S0 if and only if X=Y
- Symmetric
SX,Y=SY,X
- Triangle Inequality –
SX,YSY,Z≤ZX,Y+SY,ZS(X,Z)
The metric is said to be asymmetric if it satisfies the following properties.
- Non Negative
D(X,Y)≥0
- Reflexive
DX,Y=0if and only if
X=Y
- Symmetric
DX,Y=D(Y,X)
- Triangle Inequality
DX,Y+D(Y,Z)≥D(X,Z)
In spectral clustering similarity measure is used to convert data to overcome the issues related to lack of convexity in the form of the data distribution. There are various similarity measures and some of them are explained below.
Jaccard Similarity – It measures the similarity between the objects of binary values. It is specially used for handling asymmetric binary attributes. It is usually done by choosing the number of attributes that both objects have in common and divide it by the total number of objects. The jaccard similarity is given by
JA,B=A∩BA∪B = A∩BA+B-A∩B
where {A,B} is the given sets.
Arepresents the number of elements.
A∩Brepresents the number of elements on both sets
A∪Brepresents the number of elements on either sets
Cosine Similarity – It is used to measure the similarity between two vectors by measuring the cosine of angle between them. When the angle is 0, the cosine function is equal to 1 and it’s less than one for other values. If the angle between the vectors shortens then there is more similarity between the vectors [53,57]. The formula for cosine similarity is given as
Sx,y=cosθ=x.yx*y
Dice Similarity – It is the similarity measure related to Jaccard index. Given two datasets X and Y, then the coefficient is given as
S=2|x∩y|x+|y|
The coefficients are calculated for two strings x and y as
S=2ntnx+ny
where
2ntis the number of character bigrams in X and Y,
Your thesis deserves more than a rushed final draft.
A compelling thesis requires a defensible argument, rigorous evidence, and polished academic writing. Our thesis specialists work with master's and doctoral students to produce well-structured model documents that meet committee and institutional expectations.
✓ Plagiarism-free · ✓ 100% human · ✓ Free revisions · ✓ Confidential
🔒 No payment to start · From 3 hrs
nxis the number of bigrams in X,
nyis the number of bigrams in Y.
Hamming Distance – It is the distance between the strings of equal length in which the number of position of the corresponding symbols are different. The hamming distance between the 2 variables (x,y) is given as dH(x,y) to the number of places where x and y are different , it can be given as the number of bits or characters that has to be altered to change one string to another. Hence the Hamming distance between two vectors
x,y∈F(n)is defined by the number of coefficients in which they differ. It measures the minimum number of substitutions needed to change one string to another and the minimum error that occurs during the transformation. Here D should satisfy the condition.
- d(x, y) = 0, iff x,y agrees to all coordinates.
- The number of coordinates in which x differ from y.
- The number of coordinates in which y differ from x.
- d(x, y) is equal to the minimum number of changes in coordinates to get from x to y.
2.5 POWER METHOD
Power method is a simple iterative method to find the dominant eigen value and eigen vector for a matrix A where λ is the largest of eigen value and
v0is the largest of eigen vector. The power method is found using[58]
vt+1=cWvt
Where
vt is the vector at iteration t.
W is the Square matrix
c is the normalizing constant to keep
vtfrom getting too large or too small.
Since the power method for approximating the eigen value is iterative the initial approximation x0 of thedominant eigen vector is chosen. The sequence of eigen vector is given as [59,60]
x1=Ax̅0
x2=Ax̅1
= A (
Ax̅0) =
A2x̅0
x3=Ax̅2
=
A(A2x̅0)=
A3x̅0
.
.
.
.
.
.
.
.
xk=Ax̅k
=
A(Akx̅0)=
Akx̅0
A good approximation is obtained for larger values of k. To analyze the convergence of the power method a detailed formulation is shown. Given an N*N matrix A, the eigen vector corresponding to the eigen value is identified. Let λ0, λ1, λ2….. λn-1 be the eigen values of A. The largest eigen value is λ0 i.e. |λ0|>|λ1|>|λ2|……………|λn|. Let there be an eigen pair (λj,
vj) and assume that the vectors
v0,
v1, v2….
vn-1be linearly independent. To start with we take an initial vector at a time 0. The vector is written as a combination of the vector that is linearly independent. Here x(0) is given as a linear combination of eigen vectors. Hence,
x(0) = γ0
v0+ γ 1
v1 + γ 2
v2 …………. γ n-1
vn-1.
If the first vector is written with a matrix A we create
x(1) =Ax(0)
= A(γ 0
v0+ γ 1
v1 + γ 2
v2 …. γ n-1
vn-1)
= γ0 A
v0 + γ1A
v1 + γ1 A
v1…… + γn-1 A
vn
Similarly
x(2)=Ax(1)
= A(
γ0Av0+
γ1Av1 +
γ2 Av2 ….
γn-1A vn-1)
But A
v0 is λ0
Your thesis deserves more than a rushed final draft.
A compelling thesis requires a defensible argument, rigorous evidence, and polished academic writing. Our thesis specialists work with master's and doctoral students to produce well-structured model documents that meet committee and institutional expectations.
✓ Plagiarism-free · ✓ 100% human · ✓ Free revisions · ✓ Confidential
🔒 No payment to start · From 3 hrs
v0 and A
v1is
λ1v1since the eigen vectors are chosen[59].
=
A(γ0λ0v0+γ1λ1v1+…..γn-1λn-1vn-1)
=γ0Aλ0v0+γ1Aλ1v1+…..γn-1Aλn-1vn-1)
Here,
Aλ0v0=λ02v0,
Aλ1v1=λ12v1.. . . . …….
Aλn-1xn-1=λn-12vn-1
On repeating for higher values we get,
xk+1=Axk
=
γ0λ0kv0+γ1λ1kv1+……γn-1λn-1kvn-1
Here
Aλ0kv0=λ0k+1v0,
Aλ2kv2=λ2k+1v2…….
Aλn-1kvn-1=λn-1k+1vn-1
xk+1=γ0λ0k+1v0+γ1λ1k+1v1+……γn-1λn-1k+1vn-1
So the general equation becomes
limk→∞xk=
limk→∞(
γ0λ0kv0+
γ1λ1kv1+
γ2λ2kv2……….
γn-1λn-1kvn-1)
Here
γ0λ0kv0 is largest in magnitude and it dominates other vectors. The direction of
v1 is insignificant and vector
v0 keeps on increasing. To fix the increasing value
v0 the vectors should be kept under control. So it is rewritten as [60]
x1=1λ0Ax0
= 1λ0A(γ0v0+γ1v1……..γn-1vn-1)
=γ0 1λ0 Av0
+γ01λ0Av0………….+γn-11λ0Avn-1
Here
Av0=λ0
v0 on substitution we get,
=γ0 1λ0 (λ0v0)
=
γ0v0
Similarly,
Av1= λ1v1=
γ1v1.Hence the first term becomes
γ0v0.
x1=γ0v0+λ1λ0v1+…+λn-1λ0vn-1
x2=1λ0Ax1
x2=1λ0A(γ0v0+γ1λ1λ0v1+……. γn-1λn-1λ0vn-1
=
γ0v0+λ1λ02v1……………
λn-1λ02vn-1
In this case the first term remains the same for any value of x and the next term has the factor
λ1λ02and so on. Here
λ1λ0is the magnitude less than 1. Repeating for k steps we get
xk+1=γ0v0+γ1λ1λ0kv1
……………
γn-1λn-1λ0k+1vn-1
So we get,
limk→∞xk=limk→∞(γ0v0+γ1λ1λ0kv1…………+γn-1λn-1λ0kvn-1)
Here the value
λ1λ0is less than 1 and when raised to the power of k they eventually go to 0. Hence, the 2nd, 3rd and the nth term gradually goes to 0 and left with the first term. So, we get [59,60]
=γ0v0+γ10v1+……γn-1(0)vn-1
=γ0v0
Finally, the component in the direction of
Your thesis deserves more than a rushed final draft.
A compelling thesis requires a defensible argument, rigorous evidence, and polished academic writing. Our thesis specialists work with master's and doctoral students to produce well-structured model documents that meet committee and institutional expectations.
✓ Plagiarism-free · ✓ 100% human · ✓ Free revisions · ✓ Confidential
🔒 No payment to start · From 3 hrs
v0is constant and the component in direction of
v1shrinks and points to
v0. Due to normalization the vector avoids itself from growing itself too long or short. Eigen vector is finding the iteration involved and it’s about its length. Thus it is derived that the process produces a vector in the direction that is leading in magnitude. Hence, the power method is given as Ax = λx.
Xi+1 =
Axi||Axi|| λ i+1 =
Axi
2.5.1 Convergence Analysis
The power method does not compute matrix decomposition. Hence, it can be used for larger sparse matrix. The power method converges slowly since it finds only one eigen vector. The starting vector x0 in terms of eigenvector of A is given by
x 0=
∑i=1naivi.
Then, xk=Axk-1 =A2xk-2 =……Akx0
∑i=1nλikaivi= λnkanvn+∑i=1n-1λ1λnkaivi
The higher the power of
λ1λnit goes to 0.That is, it converges if
λ1is dominant and if q0 has a component in the direction of corresponding eigen vector x1 . Power method can also fail to converge in case if |
λ1|=|λ2|. The convergence rate of power iteration depends on the dominant ratio of the operator or the matrix which is challenging when the dominance ratio is close to one [59].
2.5.2 Drawbacks of the Power Method
- If the initial column vector
x0is an eigenvector of A other than corresponding to
ƛ1the dominant eigen value, then it fails or converges to a wrong value [60,61].
- The convergence of the power method depends on the magnitude of the dominant eigenvalue
ƛ1and the magnitude of next largest eigenvalue. If the ratio is small then convergence become slow or can even fail if
ƛ1=ƛ1̅
- It gives only one pseudo eigenvalue and its difficult when it happens to be more than one dimension.
- It is complicated in the case of many eigen values.
- The power method needs a initial guess.
2. 6 CLUSTERING ALGORITHM USING POWER METHOD
Power Iterative Clustering (PIC) is an algorithm that clusters data using power method which is used to find the largest of eigen vector a combination of the eigen vectors in a linear manner. PIC provides a low dimensional embedding of datasets. It operates on a graph of nodes connected by weighted edges. The steps involved in PIC includes[6]
a. Similarity matrix calculation which is required in spectral clustering methods is replaced by matrix vector multiplication
b. Normalization to keep the vector constant and not making to converge or diverge and
c. Iterative matrix vector multiplication where the matrix W is combined with the vector v0 to obtain Wv0.
2.6.1 Convergence Analysis
Power iteration converges to a matrix W but the results are not significant. To analyze the convergence of power iteration clustering algorithm, let us consider a matrix W with eigen values
v1,v2∙∙∙∙∙vnand eigen vector
ƛ1,ƛ2..…..ƛn. The PIC algorithm performs power iteration for less number of iteration, an stops at its convergence limit within the clusters before reaching its final convergence. The acceleration at t is given as
δt=vt-vt-1and the vector
∈t=δt-δt-1. The threshold value is
∈̂and the iteration is stopped when
∈tα≤ ∈̂. Hence the convergence can be said as power iteration clustering algorithm converges fast locally and it is slow globally[62]. The convergence rate of the algorithm towards on the dominant eigenvector
ƛ1depends on
ƛiƛ1tfor i=2…k i.e .
ƛiƛ1t≃1since the eigenvectors are close to one.
2.6.2 Disadvantages of Power Iteration Clustering
Power Iteration Clustering is fast, efficient and scalable. It has a better ability of handling larger datasets. Both requires data matrix and similarity matrix to be fitting into the processors memory that is infeasible for very larger datasets. Its challenge lies in calculation and storage of larger matrices [6,62]. Moreover PIC finds only one eigen vector which leads to inter collision problem. Lin and Cohen [6] discovered an interesting property of the largest eigenvector of W, before the elements of
vtconverge to the constant value, they first converge to local centers that corresponds the clusters in the data[63]. PIC converges quickly at local minima but it’s slow at global minima.
2.7 EXTRAPOLATION METHODS
The requirement for finding the approximate value of the sequence is significant for any algorithm to converge. An important problem that arises often is the computing limits of the vector
xn, where
xn∈CN, N is the dimension and its huge. Such sequence converges slowly or can even diverge. This condition occurs generally for iterative solutions of any linear systems. Hence, the computational complexity is high. In order to address these problems, convergence acceleration techniques like extrapolation methods has to be applied. An extrapolation method produces a new sequence
Ânfrom a given sequence
Anthat converges fast if it has a limit. If it does not have a limit the sequence can either converge or diverge slowly. Some of the most common extrapolation techniques include Richardson extrapolation, Fixed Point Iteration, Aitken Delta Square method and the Steffensen method [8].
2.7.1 Fixed Point Iteration
It is used to determine the roots of the given function. It computes the fixed point of the given iterated function [64,65]. Given a function f with real value an d points
x0in f, the fixed point iteration is given as
xn+1=f(xn)
where n = 0,1,2…..
which has the sequence
x0, x1,…
,xnconverges to the fixed point x. Let g be a continuous function in the interval (a, b) the fixed point is calculated by constantly evaluating g at points (a,b).
2.7.2 Aitkens Technique
It is a method to speed up the convergence of a sequence that is linearly convergent. It accelerates the convergence of any sequence [62]. The advantage of this method is that it improves the linear convergence of any iterative methods.
2.7.3 Steffensen Technique
The method of combining Aitken’s process with the fixed point iteration is called the Steffensen’s acceleration technique. It attains quadratic convergence. Steffensen’s method can be programmed for a generic function on certain constraint [66]. The main drawback of this method is that the value of
x0should be chosen correctly, else the method fails.
2.8 BIG DATA ANALYTICS
2.8.1 Data Deluge
It is a situation where the incoming data is more than the capacity to be managed. The rate of data is growing at a faster rate day by day. The data was about 165 Exabyte in the year 2007. It has reached to 800 Exabyte in the year 2009. There was an increase of upto 62% than the previous year. Moreover in the year 2009 the usage of the internet has been increased by 50% per year and hence the data rate doubles every 2 years[67]. In the year 2011, the term Big Data was introduced by McKinsey Global institute. The scale dataset increased from Gigabytes to Terabytes and even to Petabytes. According to the report from IDC (International Data Cooperation) in 2011, the data created was 1.8 ZB and it has increased 9 times in these 5 years. At present 2.5 quintillion bytes of data are created every day. Google process 100 PB of data, Twitter 12 PB. These huge quantity of data’s are being obtained from social networks, bank transactions, audio and videos etc. in you tube etc.
2.8.2 Big Data Storage Mechanism
Existing storage mechanisms of Big Data may be classified into three bottom-up levels namely file systems, databases, programming models [68].
- File Systems: File systems are the foundation of the applications at upper levels and Google’s GFS is an expandable distributed file system to support large-scale, distributed, data-intensive applications.
- Databases: Various database systems are developed to handle datasets at different scales and support various applications and MySQL technology for Big Data. The following three main MySQL database are key-value databases, column-oriented databases, and document-oriented databases.
- Programming Models- The programming model is critical to implementing the application logics and facilitating the data analysis applications. However, it is difficult for traditional parallel models to implement parallel programs on a Big Data scale.
Big Data Storage –It is a storage method designed to store, manage and to process large amount of data. This data is stored such that it can be accessed easily and processed by applications to work on Big Data. The data storage subsystem in a Big Data platform organizes the collected information in a convenient format for analysis and value extraction. Existing massive storage technologies can be classified as
- Direct Attached Storage (DAS)
- Network storage
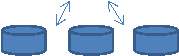
Direct Attached Storage (DAS): In DAS, numerous hard disks are connected directly with servers, and data management is held on the server rather than individual machines. The storage devices are peripheral equipment, each of which takes a certain amount of I/O resource and is managed by individual application software. It connects only limited size. The DAS storage is shown in Fig 2.1.
Your thesis deserves more than a rushed final draft.
A compelling thesis requires a defensible argument, rigorous evidence, and polished academic writing. Our thesis specialists work with master's and doctoral students to produce well-structured model documents that meet committee and institutional expectations.
✓ Plagiarism-free · ✓ 100% human · ✓ Free revisions · ✓ Confidential
🔒 No payment to start · From 3 hrs
 |